
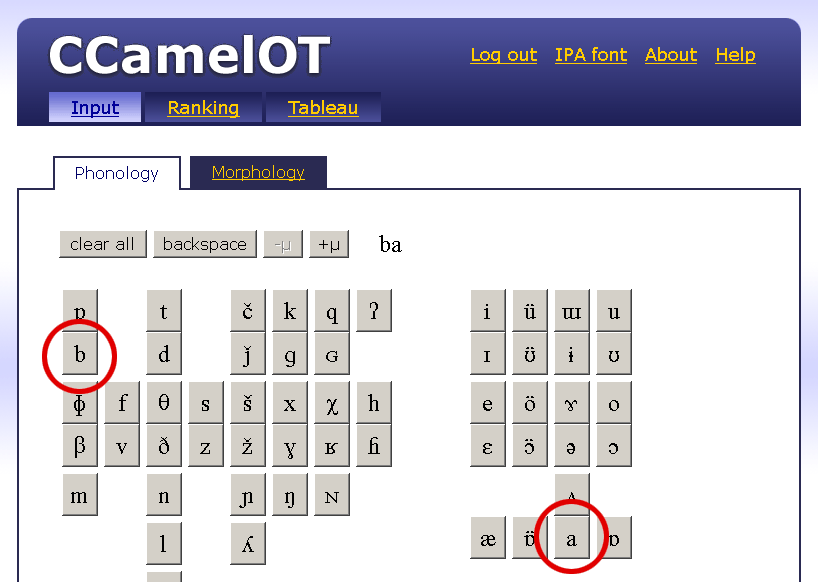

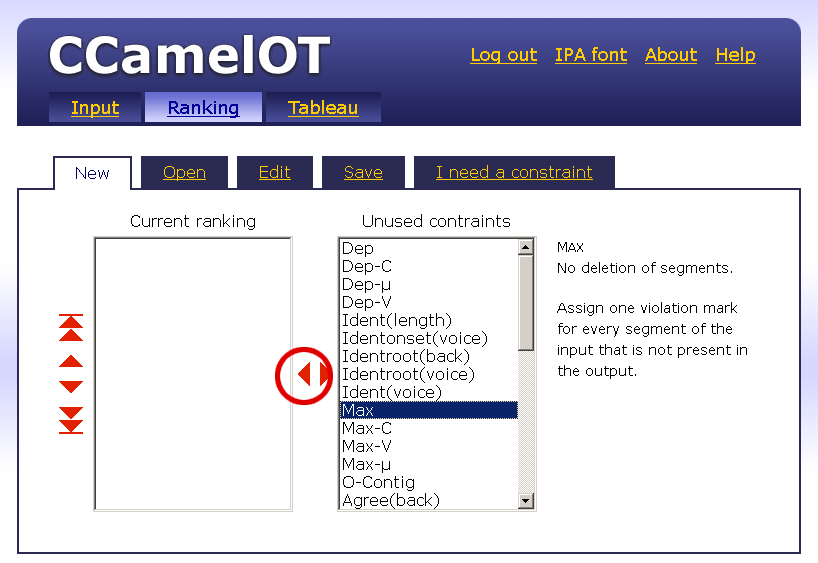

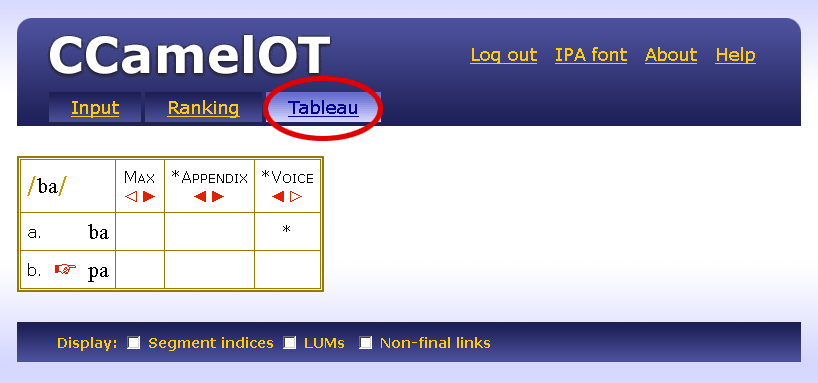
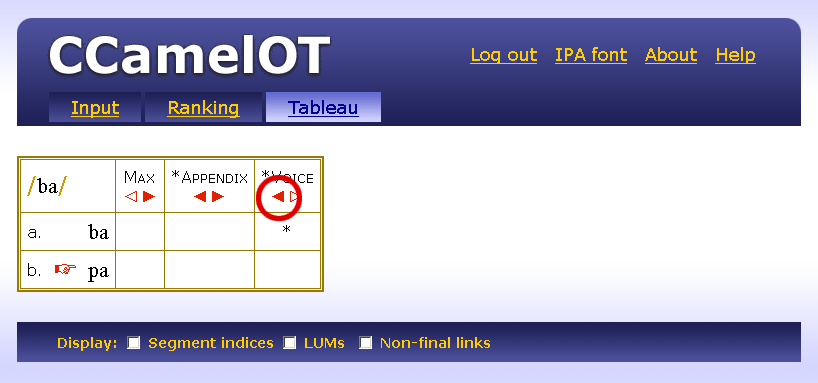

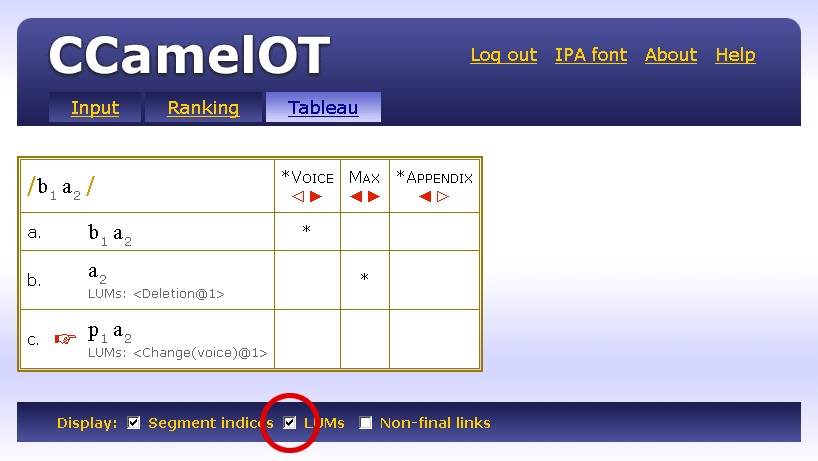



| / / | Input, Underlying Representation |
| . | Syllable boundary |
| < > | Appendix (unsyllabified segments) |
| [ ] | Root |
| < > | Candidate chain |
| Low vowels | 16 |
| Mid vowels | 15 |
| High vowels | 14 |
| Schwa | 13 |
| Barred i | 12 |
| Glides | 11 |
| r | 10 |
| l | 9 |
| (not implemented) | 8 |
| (not implemented) | 7 |
| Nasals | 6 |
| h | 5 |
| Voiced fricatives | 4 |
| Voiceless fricatives | 3 |
| Voiced stops | 2 |
| Voiceless stops | 1 |
Assign one violation mark for every segment of the output that is not present in the input.
Assign one violation mark for every consonant of the output that is not present in the input.
Assign one violation mark for every mora of the output that is not present in the input. Note that this constraint also penalizes the epenthesis of a segment that heads a mora.
Assign one violation mark for every [–high] vowel of the output that is not present in the input.
Assign one violation mark for every vowel of the output that is not present in the input.
Assign one violation mark for every segment of the output that has an input correspondent, and the [high] value of the output segment doesn't match the [high] value of the input segment.
Assign one violation mark for every output segment that has an input correspondent, and the number of moras it heads in the input is different from the number of moras is heads in the output.
Assign one violation mark for every segment of the output that has an input correspondent, and the [low] value of the output segment doesn't match the [low] value of the input segment.
For every output segment that is in a syllable onset and has an input correspondent, assign one violation mark if the output and input correspondent don't have the same value for the feature [voice].
Assign one violation mark for every segment of the output that has an input correspondent in the root, and the [back] value of the output segment doesn't match the [back] value of the input segment.
Assign one violation mark for every segment of the output that has an input correspondent in the root, and the [voice] value of the output segment doesn't match the [voice] value of the input segment.
Assign one violation mark for every segment of the output that has an input correspondent, and the [voice] value of the output segment doesn't match the [voice] value of the input segment.
Assign one violation mark for every segment of the input that is not present in the output.
Assign one violation mark for every consonant of the input that is not present in the output.
Assign one violation mark for every vowel of the input that is not present in the output.
Assign one violation mark for every mora of the input that is not present in the output. Note that this constraint also penalizes the deletion of a segment that heads a mora.
Assign one violation mark for every pair of segments that are adjacent in the input and present in the output, but not adjacent in it.
Assign one violation mark for every pair of output vowels that don't have another vowel between them, and have different values for [back].
Assign one violation mark for every pair of adjacent output obstruents that have different values for [voice].
For every root, Assign one violation mark if the leftmost segment of the root present in the output isn't the leftmost segment in the Prosodic Word.
For every root, Assign one violation mark if the rightmost segment of the root present in the output isn't the rightmost segment in some syllable.
Assign one violation mark for every morpheme boundary such that the segment before it and the segment after it belong to the same syllable.
Assign one violation mark for every word whose last segment is a vowel.
Assign one violation mark for every syllable whose initial segment is the most sonorous segment in that syllable (i.e. it is the nucleus).
Assign one violation mark for coda consonant that is not the most sonorous segment dominated by some mora.
Add up the moras of the word that dominate at least one segment (i.e. ignore floating moras). Assign one violation mark for every word that has less than two such moras.
Starting from the most sonorous segment in each syllable (i.e. ignoring the onset), add up the moras headed by the segments in the syllable. Assign one violation mark for every syllable whose non-onset segments head more than two moras.
Assign one violation mark for every segment that is not a part of some syllable.
Assign one violation mark for every syllable whose most sonorous segment is a consonant.
Assign one violation mark for every mora whose most sonorous segment is a consonant.
Assign one violation mark for every syllable whose final segment is a consonant, unless that segment is the most sonorous segment in the syllable (in which case it is the nucleus rather than the coda).
Assign one violation mark for every syllable that ends in two consonants, neither of which is the most sonorous segment in the syllable (i.e. neither is the nucleus).
Assign one violation mark for every syllable that starts with two consonants, neither of which is the most sonorous segment in the syllable (i.e. neither is the nucleus).
Assign one violation mark for every syllable whose nucleus is a vowel and the following segment in the syllable is also a vowel.
Assign one violation mark for pair of adjacent identical consonants.
Assign one violation mark for every syllable whose final segment is a glottal stop.
Starting from the most sonorous segment in each syllable (i.e. ignoring the onset), add up the moras headed by the segments in the syllable. Assign one violation mark for every syllable whose non-onset segments head more than one mora.
Assign one violation mark for every vowel that is [–high] and [–low].
Assign one violation mark for every syllable whose final segment is a low vowel.
Assign one violation mark for every consonant that's associated with more than one sylllable.
Assign one violation mark for every stop (i.e. [–cont, –son]) that is [–voice].
Assign one violation mark for every intervocalic [g].
Assign one violation mark for every segment that is [–son] and [+voice].
For every instance of epenthesis, assign one violation mark if a change of [low] crucially follows, and one violation mark if a change of [low] does not crucially precede.